Capitulo 2 Conceptos básicos de estadística y econometría
2.1 Estadística
La estadística nos permitirá que a partir de un conjunto de datos realizar análisis, inferencia, estimar distribuciones de probabilidad, es decir, es un conjunto de métodos que estudian la recolección, análisis e interpretación de datos, ayudando en la toma de decisiones o para explicar condiciones regulares o irregulares de algún fenómeno o estudio aplicado, de ocurrencia en forma aleatoria o condicional (Jeffrey 2010).
2.1.1 Conceptos básicos
Variables aleatorias: una variable aleatoria X es una función cuyos valores son números reales y dependen de una distribución de probabilidad.
Distribuciones de probabilidad: una distribución de probabilidad describe el rango de valores que puede tomar una variable aleatoria y la probabilidad asignada a cada valor o rango de valores.
Ley de los grandes números: cuanto mayor sea el tamaño de la muestra, mayor será el ajuste entre la distribución teórica sobre la que se basa la muestra. La frecuencia relativa de los resultados de un cierto experimento aleatorio, tiende a estabilizarse en cierto número, que es precisamente la probabilidad, cuando el experimento se realiza muchas veces.
Teorema del limite central: la media muestral de un conjunto de n variables muestreadas en forma independiente a partir de una misma distribución f(x) se ajusta a una distribución aproximada Normal. En otras palabras, la distribución del promedio de un conjunto de variables aleatorias depende tanto de la cantidad de variables aleatorias promediadas como de la incertidumbre aportada por cada variables.
2.1.1.1 Tipo de variables
Variable es una característica que al ser medida en diferentes individuos es susceptible de adoptar diferentes valores. Se tienen variables cualitativas (expresan características, cualidades) y cuantitativas (expresan cantidades numéricas).
Una variable aleatoria es una característica que toma diferentes valores, cada uno con una probabilidad previamente definida. Este valor es la realización de la variable.
Tipos de variables: cualitativas y cuantitativas
2.1.2 Momentos estadísticos
Las distribuciones de probabilidad, se describen mediante 3 tipos de parámetros, indicadores o “estadísticos”, que son valores que muestran alguna de sus características:
- Estadístico de Tendencia Central: es un valor representativo de un conjunto de datos, el primer momento, mide la tasa esperada de retornos sobre un proyecto en particular, los estadísticos comunes incluyen a la media (promedio), mediana (centro de la distribución) y moda (valor de ocurrencia mas frecuente).
- Estadístico de Dispersión: El segundo momento, dan una idea de qué tan aglomerado o disperso se pueden encontrar los valores alrededor del centro de la distribución.
- Estadístico de Forma: Precisan otras características particulares de la distribución, como puede ser:
- Su simetría ( tercer momento)
- La importancia relativa de los valores extremos ( cuarto momento)
2.1.2.1 Tendencia central
La expresión corriente de promedio, suele en la mayoría de los casos referirse a la media aritmética.
Tendencia central: Media (promedio), mediana (centro de la distribución), moda (el valor que se presenta con mayor frecuencia).
Es la medida de posición o promedio más conocida, por su gran estabilidad es la preferida en el muestreo, sus fórmulas admiten tratamiento algebraico. Su desventaja principal, es ser muy sensible a cambios en sus valores u observaciones, también, cuando alguno de sus valores extremos es demasiado grande o pequeño (outliers).
Se define como la suma de todos los valores observados, divididos por el número total de observaciones
\[\bar{X} = \mu = \frac{\sum_{i=1}^n x_i}{n}\] Propiedades de la media:
- La suma de las desviaciones respecto a la media, siempre serán iguales a cero.
- La media aritmética de una variable por una constante, es igual a la constante por la media aritmética de la variable.
- La media aritmética de una constante es igual a la constante.
- La media aritmética de una variable más una constante, es igual a la media aritmética de la variable más la constante.
- La media aritmética de la suma de dos variables, es igual a la suma de las dos medias correspondiente a las dos variables.
- La media aritmética de dos muestras, es igual, a la media ponderada de las submuestras, siendo sus ponderaciones los tamaños de esas submuestras.
2.1.2.2 Dispersión
Mide la extensión de una distribución, la cual es una medida de riesgo. La extensión o amplitud de una distribución mide la variabilidad de una variable, es decir, el potencial de que una variable pueda caer en diferentes regiones de la distribución, en otras palabras, los potenciales escenarios de resultados.
Se puede estimar a partir de: varianza, desviación estándar, rango, coeficiente de variación, percentiles.
Las medidas de dispersión más conocidas y utilizadas son la varianza y la desviación típica o estándar. Esta última, es la raíz cuadrada de aquélla.
La varianza se define como: la media aritmética de los cuadrados de las diferencias (desviaciones) entre los valores que toma la variable y su media aritmética. Su símbolo es \(S^2\) en la muestra, \(\sigma^2\) (sigma al cuadrado) en la población.
Se utiliza el momento de orden 2 con respecto a la media.
\[S^2 = \frac{\sum_{i=1}^n (x_i - \bar{x})^2}{n}\]
\[\sigma^2 = \frac{\sum_{i=1}^n (X_i - \mu)^2}{N}\]
Desviación típica o estándar: indica en promedio como se dispersa una observación con respecto a la media aritmética. También es útil para describir cuanto se apartan las observaciones individuales con respecto a la media, se le conoce como resultado estándar.
\[S = \sqrt{S^2}\] \[\sigma = \sqrt{\sigma^2}\]
En otras palabras: - Es la distancia que tienen los datos con respecto a su media - La desviación estándar es la raíz cuadrada de la varianza - Para una distribución normal cerca del 68% de la probabilidad está dentro de + o – una desviación estándar de la media (95% para 2 y 99% para 3)
Regla empírica: Distribución de probabilidad de variable aleatoria continua cuya forma es simétrica y acampanada y sus parámetros son una media y una desviación estándar.
- Alrededor del 68% de las observaciones se encuentran en el intervalo 𝜇±𝜎.
- Alrededor del 95% de las observaciones se encuentran en el intervalo 𝜇±2𝜎.
- Alrededor del 99% de las observaciones se encuentran en el intervalo 𝜇±3𝜎.
2.1.2.3 Simetría
Coeficiente de asimetría: \[m_3 = \frac{\sum_{i=1}^n (x_i - \bar{x})^3}{n}\] 1. \(A_s = 0\) la distribución es simétrica. 2. \(A_s >0\) la distribución es asimétrica positiva. 3. \(A_s <0\) la distribución es asimétrica negativa.
El alargamiento es la medida de la asimetría de una distribución. Mide la desviación de una distribución.
Una distribución normal no está alargada y tiene un alargamiento de 0. En distribuciones alargadas, la diferencia entre el resultado más probable y el promedio puede ser muy significativa.
Es importante conocer y estudiar las colas de la distribución ya que nos van a indicar valores extremos, por ejemplo, si seanaliza los rendimientos de una empresa, la cola izquierda indica pérdidas y la cola derecha ganancias.
2.1.2.4 Curtosis
La curtosis es una medida de altura de la curva y por tanto está representada por el cuarto momento de la media.
\[m_4 = \frac{\sum_{i=1}^n (x_i - \bar{x})^4}{n}\] 1. \(A_p = 3\) la distribución es normal o mesocúrtica. 2. \(A_p >3\) la curva es leptocúrtica o apuntado. 3. \(A_p <3\) la curva es platicúrtica o achatada.
La curtosis mide la forma de una distribución, en otras palabras, mide el punto más alto de una distribución.
Una distribución normal tiene una curtosis de 3 ó un exceso de curtosis de 0.
Distribuciones más picudas tienen valores de curtosis más altos, generalmente se calcula el exceso de curtosis haciendo referencia a la normal
2.1.3 Correlación
Un análisis de correlación permite diagnosticar el nivel o grado de asociación entre dos variables. Así pues, mediante el coeficiente de correlación de Pearson (r), se puede apreciar si las variables estan asociadas positivamente (r > 0); si se mueven en direcciones opuestas (r < 0); o si no están relacionadas o son independientes (r = 0).
Por otra parte, el coeficiente de correlación de Pearson se utiliza para relaciones líneas y no así para relaciones no lineales, donde se emplea el coeficiente de Spearman.
\[ r = \frac{\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum_{i=1}^{n}(x_i-\bar{x})^2}\sqrt{\sum_{i=1}^{n}(y_i-\bar{y})^2}} \]
2.2 Econometría
2.2.1 Regresión lineal
El objetivo de la regresión lineal es minimizar la distancia entre los puntos de un diagrama de dispersión (considerando que una linea no puede pasar perfectamente por todos los puntos). Ahora bien ¿Pueden ustedes encontrar la recta que minimice la distancia entre todos los puntos? Si son honestos seguro respondieron que no (Soundalyarao 1996).
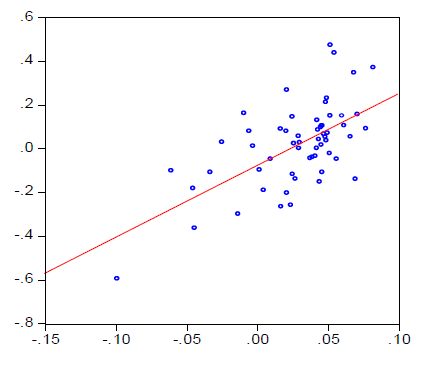
Figure 2.1: Regresión lineal
2.2.1.1 Método de Mínimo Cuadrados Ordinarios
La Función de Regresión Lineal Poblacional: \[Y_i = \beta_0 + \beta_1 X_i + \epsilon_i \] La Función de Regresión Lineal Muestral: \[\hat{Y}_i = \hat{\beta}_0 + \hat{\beta}_1 X_i + \hat{\epsilon}_i\] Lo que se pretende es estimar los parámetros mediante el {}, así pues, se minimiza en la muestra el error cuadrático medio (mean squared error): \[\widehat{MSE}(\hat{\beta}_0, \hat{\beta}_1) \equiv \frac{1}{n}\sum_{i=1}^{n}{(Y_i - (\hat{\beta}_0 + \hat{\beta}_1 X_i))^2}\] Depúes de minimizar el error cuadrático medio se obtiene:
- El intercepto: \[\hat{\beta}_0 = \bar{Y} – \hat{\beta}_1 \bar{X}\]
- La pendiente: \[\hat{\beta}_1 = \frac{\sum(X_i – \bar{X}) (Y_i – \bar{Y})} {\sum(X_i – \bar{X})^2}\]
2.2.1.2 Ejemplo de un modelo de regresión
¿Cuál es la relación entre el salario y el nivel de eduación de las personas?
Se puede considerar que a mayor nivel de educación mayor salario, así también, otras variables.
Modelo de regresión: \(\mathrm{Salario}_{t}=\alpha+\beta_{1}\mathrm{Niv.eduación}_{t}+\beta_{2}\mathrm{Exp.laboral}_{t}+\beta_{3} \mathrm{Edad}_{t}+\beta_{4}\mathrm{Género}_{t}+\beta_{5}\mathrm{Skill}_{t}+\epsilon_{t}\)
Se presentan las siguientes preguntas:
- ¿Cómo interpretamos \(\beta_{1}\)?
- Un año de educación adicional se correlaciona con un \(\beta_{1}\) aumento de unidades en el salario de un individuo (controlando por todas las otras variables).
- ¿Los términos \(\beta_{i}\) son parámetros de población o estadísticas de muestra?
- Las letras griegas denotan parámetros de población y suus estimaciones obtienen sombreros, por ejemplo, \(\hat{\beta}_i\).
- ¿Podemos interpretar las estimaciones para \(\beta_{1}\) como causal?
- ¿Qué es \(\epsilon_{t}\)?
- ¿Qué supuestos imponemos al realizar estimaciones con MCO?
- Supuestos:
- La relación entre el salario y las variables explicativas es lineal en parámetros, y \(\epsilon_{t}\) afecta de manera aditiva.
- Las variables explicativas son exógenas, es decir, \(E[\epsilon_{t}|X] = 0\).
- Por lo general, también ha asumido algo como:
\(E[\epsilon_{t}] = 0\), \(E[\epsilon_t^2] = \sigma^2\), \(Cov[\epsilon_t \epsilon_j] = 0\) for \(t \neq j\). - Se distribuye normalmente \(\epsilon_t\).
¿Qué tan importantes pueden ser la regresión por mínimos cuadrados ordinarios (MCO)?
Es una herramienta poderosa y flexible. Sin embargo, los resultados que se pueden estimar requirieron suposiciones.
La vida real a menudo viola estos supuestos.
Entonces, la pregunta es: ¿qué sucede cuando violamos estos supuestos?
- ¿Podemos encontrar una solución? (Especialmente: cómo/cuándo es \(\beta\) causal?)
- ¿Qué sucede si no aplicamos (o no podemos) una solución?
MCO todavía hace algunas cosas asombrosas, pero necesita saber cuándo ser cauteloso, confiado o dudoso.
Referencias
Jeffrey, Wooldridge. 2010. Introduccion a La Econometria. Un Enfoque Moderno. 4ª edición. Cengage.
Soundalyarao, Maddala Gangadharrao. 1996. Introducción a La Econometría. 1ª edición. Capital federal, México: Prentice Hall Hispanoaméricana S.A.